Также рекомендуется использовать операционную систему на базе Linux. Это не всегда необходимо, но если вы хотите исследовать эту область дальше, вы можете установить одну из последних версий Ubuntu, например. Большинство нейронных сетей и руководств разрабатываются под Linux.
Большой разбор: ИИ научился играть в динозаврика из Chrome
Это тот редкий случай, когда лучше не выходить в Интернет.
В браузере GoogleChrome есть игра про динозавров. Если Интернет отсутствует, браузер отображает следующее
Недавно Chrome добавил возможность играть в эту игру онлайн: type chrome: // dino
Австралийский разработчик по имени Эван (YouTube-CodeBullet) создал нейронную сеть, которая сама играет в игру, и опубликовал видео об этом.
Спойлер: в конце концов, искусственный интеллект ломает игру.
Вот пошаговый обзор того, что он сделал и чего не сделал. Само видео на английском языке, поэтому если вы не понимаете английский, рассматривайте эту статью как смысловой перевод происходящего.
Создание игры
Вы можете научить TN играть в эту игру, просто глядя на экран и анализируя все, что там происходит. Однако производительность TN ограничена скоростью экрана. Это означает, что TN не сможет играть на высокой скорости. Кроме того, поскольку вы хотите играть на высокой скорости, эффективнее интегрировать TN непосредственно в игру.
Гендер и стойкие характеры. Чтобы как можно быстрее опробовать первую версию игры, Эван не рисует динозавров, а создает прыгающие прямоугольники. То же самое относится и к поверхностям. Это простая линия, а не дорога с перспективой и песком в случайных точках. Пока что все, что вы можете сделать в игре, — это перепрыгнуть прямоугольник в точку.
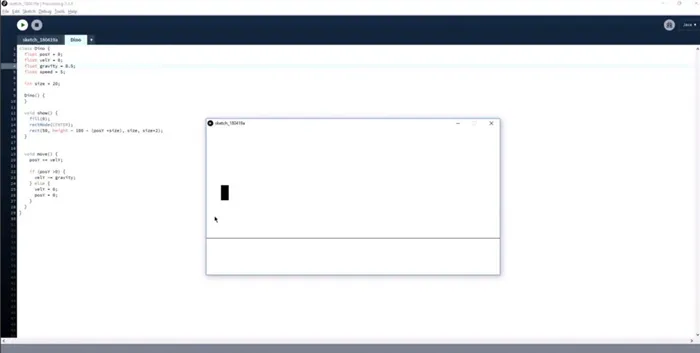
Кстати, если вы посмотрите игру в Chrome, то заметите, что динозавры бегают по земле (с органами чувств), но их X-координаты не меняются на экране. Вы можете представить, что бежит не динозавр, а кактус, летящий на скорости. Иллюзии!
Движение и препятствия. На следующем этапе Эван перемещает кактус в сторону динозавра. Однако на рисование кактуса уходит много времени, поэтому он по-прежнему прямоугольный. Сначала сделайте что-то небольшое и посмотрите, что произойдет.
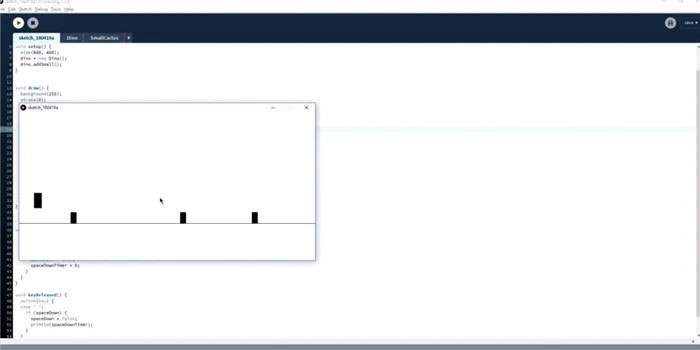
Пока что персонаж прыгает, а прямоугольник движется. Следующий шаг — добавить кактусы разной высоты и ширины, как в оригинальной игре. Опять же, это все еще прямоугольники: это все еще прямоугольники.
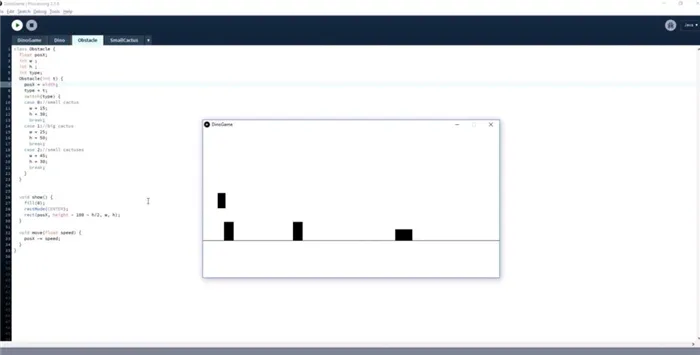
Смерть от кактуса. Последнее, что делает Эван, это добавляет условие к игре. Согласно этому, как только персонаж дотрагивается до кактуса, он умирает. Это делается путем простой проверки пересечения первого и второго объектов. Если к кактусу прикоснуться, он погибает.
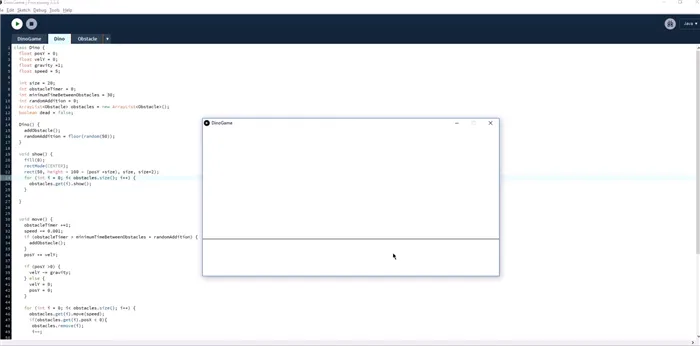
Теперь все готово для первой версии. Вы можете поиграть и проверить, все ли работает.
Эван не стал сразу планировать всю игру с динозаврами, графикой и красивыми кактусами. Вместо этого он создал схему и физику игры, убедился, что все работает, а затем заменил прямоугольники динозаврами и кактусами, а линии пола — песчаными дорожками. Он отделил их всех от игры и поместил в расписание.
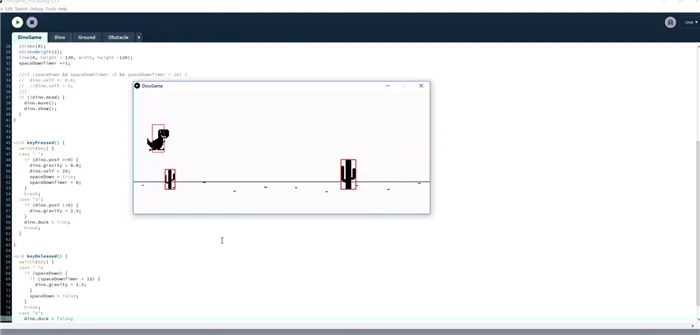
Красные прямоугольники — это метки границ объектов для обнаружения столкновений. Позже они исчезнут.
Не хватает только того, как Эван создал птиц. Птицы могут летать низко, высоко или очень высоко. Однако мы уже знаем, что они начинались как прямоугольники на линии, а позже были заменены изображениями птиц.
Динозаврам также пришлось научиться изгибаться — их прямоугольники уменьшенной высоты превратились в динозавров, изогнутых вниз:…
Нейросеть
Когда игра будет готова, ее можно будет связать с искусственным интеллектом. Для этого Эван написал простую самообучающуюся нейронную сеть, которая работает на принципах обучения с подкреплением. Это означает, что искусственный интеллект изначально ничего не знает о мире, в который он помещен, и его задача — определить правила, которые помогут ей играть в игру как можно лучше.
Очень просто, это работает следующим образом.
- Первое поколение сети —
- Запустите его в игре и посмотрите результаты, с
- первая сгенерированная версия, с наилучшими характеристиками или с большим количеством обслуживания и удалением других.
- Эти удачные версии снова запускаются в игре, и вы увидите, что они показывают наилучшие результаты,…
- Младшие счастливчики сохраняются, остальные удаляются, и так повторяется до тех пор, пока ТН не научится завершать игру.
Первая версия TN, созданная Эваном, прыгает случайно и, если повезет, перепрыгивает через кактусы.
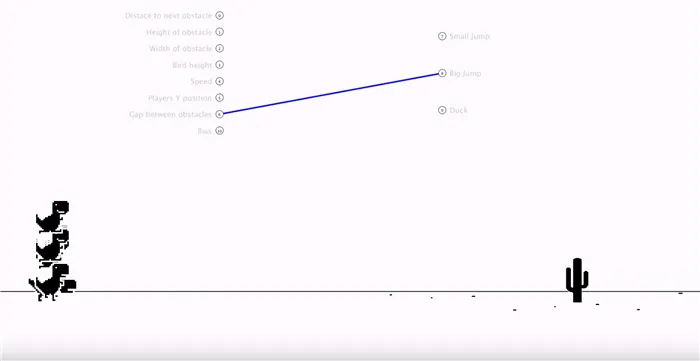
Синяя линия — связь между параметрами игры и действиями динозавра. Пока что она очень примитивна.
Первые поколения искусственного интеллекта имели примитивную тактику. Прыгайте и надейтесь, что интервал между прыжками соответствует расстоянию между кактусами. Это не сработало, и поэтому до седьмого поколения было установлено, что нейронная сеть коррелирует с расстоянием до препятствия, расстоянием между препятствиями и расстоянием для прыжка.
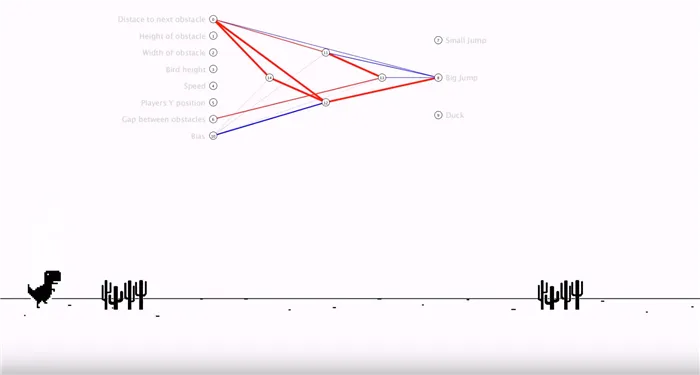
Цветные линии выше — это связи внутри нейронной сети в упрощенном виде. Вы можете видеть, как одни параметры начинают влиять на другие.
Искусственный интеллект знает, как подождать, пока кактус подойдет достаточно близко, чтобы прыгнуть, а не прыгнуть случайно.
Интересный момент: поскольку Эван использует сеть нейронов, которая обучается самостоятельно, он может видеть, как динозавры вторгаются или распадаются на множество частей в некоторых местах.

Это происходит потому, что искусственный интеллект всегда контролирует, лучше ли прыгнуть чуть раньше или чуть позже. Кроме того, в тех случаях, когда стратегия дает лучшие результаты, чем другие варианты, TN основывает эту стратегию на следующем поколении, которое является фундаментальным.
25-е поколение — вот реакция на низко летящих уток: нужно поворачивать. 40-е поколение — коммуникации изменились, чтобы приспособиться к высокой скорости игры, когда кактусы перелетают из одного конца в другой за одну секунду. Поколение 4 — Визуально различия менее очевидны, но некоторые линии связей толще. Это означает, что одни факторы и параметры оказывают большее влияние на другие.
Изображение из графика изображения (графическое представление содержимого изображения). Используются однослойная (CRN) графическая сеть и сеть прогрессивного улучшения (CRN).
Способно ли глубокое обучение справиться лучше?
Цель данного документа — определить, можно ли достичь более эффективных стратегий с более глубоким обучением. Это достигается следующим образом:.
- Используйте симулятор блэкджека для генерации данных из предыдущего материала (с модификациями, подходящими для алгоритмического обучения).
- Создать код для обучения нейронной сети и сыграть в блэкджек (желательно оптимальный).
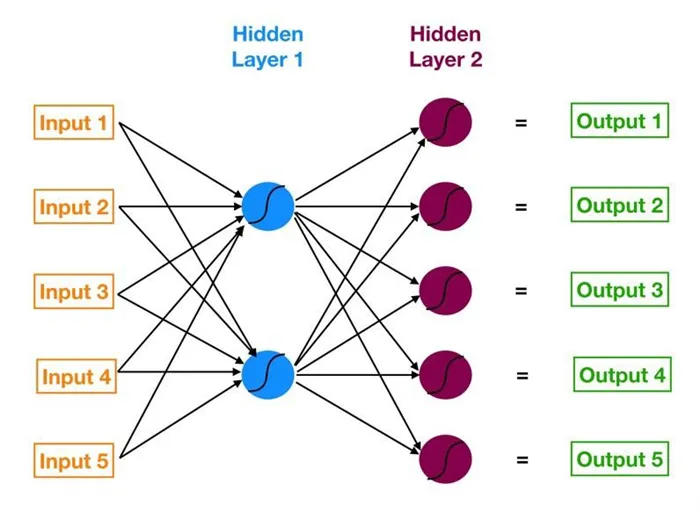
Прежде чем перейти к самому процессу обучения, давайте вернемся назад и кратко рассмотрим плюсы и минусы использования нейронных сетей в данном случае. Нейронные сети — это очень эффективные алгоритмы, которые можно условно сравнить с глиной. Они адаптируются к обзору доступной информации практически без изменений. Например, данные линейной регрессии могут быть легко обработаны нейронными сетями. И слои, и нейроны сети могут находить нелинейные взаимосвязи данных, заложенные глубоко внутри них.
Однако за эту гибкость приходится платить. Нейронные сети — это модели «черного ящика». В отличие от регрессии, где вы можете увидеть, как именно модель принимает решения, исследуя факторы, нейронные сети не обладают такой прозрачностью. Существует также риск переобучения, когда выборочные данные перестают быть обобщенными. Эти недостатки необходимо учитывать и принимать дополнительные меры для их устранения. Однако это не повод отказываться от использования нейронных сетей.
Генерация тренировочных данных
Прежде чем начать обучение нейронной сети, необходимо определить, как структурировать данные, чтобы созданная вами модель была полезной.
Что вы можете предсказать? Существуют две потенциальные целевые переменные.
- Шансы на поражение. Однако это полезно только в том случае, если есть шанс увеличить или уменьшить ставку, что в блэкджеке невозможно.
- Лучшим вариантом действий будет разыграть еще одну карту или сложить. Таким образом, целевая переменная — это решение о том, какое действие является идеальным в конкретной ситуации. То есть, больше тяг или складок.
Нет абсолютно никакой необходимости в том, чтобы сеть совершала ошибки. Просто убедитесь, что он правильно предсказывает в большинстве случаев. Спросите, как это сделать:.
- Раздайте карты игрокам и дилеру.
- Проверьте, есть ли у одного из них 21
- Выполнить действие (draw или fold), и
- Смоделируйте игру до конца и запишите результат.
Симулируемый игрок принимает только одно решение и поэтому может оценить его качество на основании того, выиграл он или проиграл игру.
- Если игрок выиграл с помощью карты, то карта (Y = 1) была правильным решением.
- Если игрок проиграл картой, то пас (Y = 0) был правильным решением.
- Если игрок пасовал и выиграл, то фолд (Y = 1) был правильным решением.
- Если игрок пасовал и проигрывал, то карты (Y = 0) были правильным решением.
Это позволяет обучить модель так, чтобы на выходе получалось предсказание правильного действия (карта или пас). Код аналогичен тому, который использовался в прошлый раз. Основные признаки следующие.
- Открытая карта лидера (вторая карта закрывается игроком)
- Общая стоимость карт в руке игрока.
- Проверяет, есть ли у игрока туз
- Действие игрока (карта или пас)
Цель — определить правильное решение на основе вышеприведенной логики.
Тренировка нейронной сети
Для нейронной сети используется библиотека Keras. Сначала добавьте все необходимые импорты.
Далее определим входные переменные для обучения сети. Feature_list — это переменная со столбцами, представляющими вышеуказанные характеристики. Блок данных model_rf содержит данные из выполняемой симуляции.
Код для запуска и обучения нейронной сети очень прост. Первая строка создает нейронную сеть последовательного типа, которая представляет собой линейную последовательность уровней нейронной сети. Следующая строка добавляет слои один за другим (высокая плотность — самый простой тип слоя, который представляет собой набор нейронов) и числа, такие как 16, 128 и т.д. Показано количество нейронов в каждом слое.
Наконец, на последнем уровне необходимо выбрать функцию активации. Он преобразует необработанный результат в более содержательную форму. Следует отметить два момента. Во-первых, поскольку предсказание основано на двух возможных выходах (двухклассовая задача), последний слой содержит только один нейрон. Во-вторых, используется сигмоидная функция, потому что нейронная сеть действует как бухгалтерская регрессия и должна предсказать правильное действие — разметку (Y = 1) или обгон (Y = 0). Другими словами, вам нужно знать вероятность того, что карта является правильным выбором.
Последние две строки указывают на используемую функцию потерь (кросс-функция — это функция потерь, используемая в модели вероятностной классификации) и сопоставляют данные с моделью. Немного больше экспериментов с количеством нейронов позволят получить еще более эффективные сети.