Трансформирующие проекты — например, создание скульптуры, которую вы спроектировали с помощью DALL-E — разрешены, и эти проекты принадлежат вам, а не OpenAI.
🎨 How to use DALL•E
What is DALL·E?
DALL-E — это веб-приложение ИИ, разработанное компанией Open AI. Он использует искусственный интеллект для преобразования предложений (например, «Серая лошадь скачет по пляжу на закате») в изображения. Он также может принимать загруженные изображения и изменять их.
Is DALL•E real?
Да, мое милое летнее дитя — уверяю тебя, это вполне реально!
How do you use DALL•E?
Использование DALL-E для создания графики искусственного интеллекта чрезвычайно просто.
Существует три основных способа создания изображения: Текстовые инструкции, варианты и правки.
Рассмотрим сначала самый привычный метод — текстовые подсказки.
How do you prompt DALL•E with text?
Основной интерфейс для DALL-E таков: буквально просто текстовое поле.
Нажмите кнопку «Generate» и подождите около двадцати секунд.
DALL-E представляет вам десять шесть изображений по вашей подсказке.
На этом этапе вы можете щелкнуть на любом изображении, чтобы просмотреть его в полном размере (1024px x 1024px квадрат), скачать его в формате PNG, сохранить в личной коллекции или создать ссылку, чтобы поделиться. Это действительно так просто.

Вот и все! Если хотите, вы можете изменить формулировку своего описания, чтобы получить другой результат, или просто запросить что-то совершенно другое. (Одна оговорка: в настоящее время пользователи ограничены 50 запросами в течение 24 часов).
Вы можете спросить DALL-E не только с помощью предложения, но и с помощью картинки.
Есть два способа сделать это: вариант или редактирование.
How do DALL·E variations work?
В одном из вариантов вместо письменного текста просто задается вопрос DALL-E с картинкой.
В соответствии с представленной фотографией, DALL-E генерирует девять пять других изображений, которые, по его мнению, очень похожи.

С помощью DALL-E можно быстро и легко создавать вариации предыдущих результатов — кнопка расположена прямо над изображением.
Это хороший способ приближаться к желаемому результату шаг за шагом.
В предыдущем примере мы не указали, какой художественный стиль мы хотим видеть у нашей астронавтки Джейн Остин, и поэтому получили целый ряд результатов — одни больше похожи на красочные поздравительные открытки, другие немного более живописны.
Результат, который мы выбрали выше, имеет довольно пронзительный, религиозный характер: Джейн смотрит на звезды — или на Бога?
Итак, давайте продолжим и создадим вариации этого изображения….
Через двадцать секунд DALL-E предлагает пять новых вариантов.

Заметно, что наши последние астронавты разделяют царственный, религиозный художественный стиль закачки, с преобладанием скорбных выражений лица. Все они также имеют схожую планировку.
Конечно, теперь вы можете создавать вариации любой из этих новых версий.
Если продолжать в том же духе на протяжении нескольких поколений, можно довольно далеко отойти от своей первоначальной эстетики — и часто оказываешься в совершенно неожиданном месте, в визуальном стиле, который раньше не знал, как описать. Это как китайский шепот, только для картин.
What is out-painting?
В отличие от «рисования», когда мы используем инструмент «редактирование», чтобы стереть внутренние части изображения, а затем позволяем DALL-E заполнить пробелы, мы можем позволить DALL-E показать «больше» изображения.
Мы берем наше исходное изображение и переносим его в Photoshop (или что-то подобное), а затем изменяем его размер, оставляя прозрачную область вокруг изображения.
Затем мы экспортируем его как PNG и загружаем наш новый файл в DALL-E.
↔️ Практическое использование этого инструмента — быстрое улучшение результатов DALL-E, когда кадрирование изображения слишком узкое и части объекта обрезаны.
Существуют и более экспериментальные приложения.
Как и в случае с вариациями, вы можете выполнять этот процесс рекурсивно, увеличивая масштаб «все дальше и дальше» от первоисточника — с творческими результатами.
Поскольку этот метод использует функцию «Редактировать», вы можете ввести описание, которое диктует, что DALL-E должен рисовать каждый раз в новом регионе, и таким образом включить новые элементы — или даже изменить стиль иллюстрации!
🖼 И снова, вы можете обесцветить любое изображение из открытых источников, общественного достояния или созданное самостоятельно, просто окружив его прозрачными пикселями, а затем загрузив его.
🤩 Например, это «остаток Моны Лизы»!
How can I create landscape/portrait photos in DALL•E?
DALL-E дает только квадратные результаты, но с помощью out-painting можно сварить более широкие изображения!
Просто загрузите вывод, перенесите его в программу редактирования фотографий и перетащите на одну сторону холста, оставив созданное пустое пространство прозрачным.
Сохраните этот файл в формате PNG и перейдите в DALL-E, выберите «edit» и спросите, что должно появиться на пустом месте (мы попросили «alien spaceship») — затем выберите вариацию.
Теперь вы можете легко совместить это второе изображение с оригиналом в Photoshop, чтобы создать более широкую сцену!

Нет границ для вашей фантазии — эпические фрески, панорамы и даже вертикальные изображения, уходящие в небо, — все зависит от вас.
На следующих изображениях мы использовали аутпейнтинг для создания портретных изображений размером с «Историю Instagram». Поскольку мы можем описать, что писать в пробелах, мы можем поэкспериментировать с описанием персонажа, а затем создать отдельное описание для вышеупомянутой формы пришельца.


Можно даже создавать очень большие квадраты, простирающиеся в обоих направлениях сразу — но нужно быть методичным, чтобы убедиться, что все совпадает!
Мы также спросили Екатерину, какие запросы пользователей DALL-E 2 и Midjournal могут вызвать проблемы с точки зрения российского законодательства.
DALL-E 2 — эволюция искусственного интеллекта
В 2022 году разработчики OpenAI анонсировали усовершенствованную нейронную сеть DALL-E 2, основанную на своей предшественнице. Эта нейронная сеть способна генерировать невероятные фотореалистичные изображения, используя только заданные фразы и полные предложения. Посмотрите, на что он способен!

DALL-E 2 может работать в трех режимах:
- Создайте изображение с нуля.
- Создайте новую вариацию существующего изображения с нуля.
- Закрасьте части изображения.

Последний режим буквально невероятен! Посмотрите, как DALLE 2 «думает» о недостающих частях известного изображения и создает более целостное изображение:



Если вы не заметили, пары выше — это оригинал, а ниже — работа DALLE 2. Видео, в котором вы сможете увидеть другие варианты вышеуказанных таблиц, а также некоторые другие вариации:
Кстати, фоновую музыку в этом видео я создал за несколько минут с помощью Mubert.
Чем отличается нейросеть DALL-E 2 от DALLE?
Преимущества DALL-E 2 перед первой версией нейронной связи заключаются в следующем:
- DALL-E 2 создает гораздо более реалистичные изображения в лучшем качестве. Конечный результат быстрее становится доступным оператору.
- Он может выполнять различные операции по редактированию фотографий на изображении. Например, DALL-E 2 может добавлять объекты в определенную область изображения, при этом тени, отражения и текстуры уже учтены искусственным интеллектом.
- Он лучше понимает всю сцену и лучше распознает объекты на изображении и взаимосвязи между ними.
- Способен воспроизводить изображения в разных стилях, создавая качественно различные вариации одного и того же образа.
- В DALL-E 2 вы можете добавить еще одно изображение к оригиналу, после чего нейронная сеть объединяет изображения и создает из них новую вариацию.
Как попробовать DALL-E 2?
Инженеры OpenAI осознают революционный характер разработки, что может привести к бесконтрольному применению в массовом производстве.
Хотя в обозримом будущем OpenAI сделает код DALL-E свободно доступным, в настоящее время опробовать нейронную сеть можно только по приглашению, присоединившись к списку ожидания. С мая 2022 года более 600 «простых смертных» получат доступ к нейронной сети.
Вы также можете подать заявку на доступ к DALL-E 2 по этой ссылке: https://labs.openai. com/waitlist Убедитесь сами, что это не DALL-E 2, а большая команда художников, запертых в душном офисе и регулярно публикующих свои творения под видом результата работы искусственного интеллекта : )
Ну, а пока у вас нет доступа, я рекомендую вам зайти в instagram openaidalle, где разработчики регулярно делятся своими крутыми кистями с искусственным интеллектом.
Например, вы можете загрузить старую картину, находящуюся в общественном достоянии, такую как «Мона Лиза», или другую свободную работу, например, фотографию Creative Commons.
lucidrains/DALLE2-pytorch
Это обязательство не принадлежит ни к одной ветви этого репозитория и может принадлежать к ветви вне репозитория.
Используйте Git или проверяйте с помощью SVN, используя URL.
Работайте быстро с помощью нашего официального CLI. Узнайте больше.
Launching GitHub Desktop
Если ничего не происходит, загрузите GitHub Desktop и повторите попытку.
Launching GitHub Desktop
Если ничего не происходит, загрузите GitHub Desktop и повторите попытку.
Launching Xcode
Если ничего не происходит, загрузите Xcode и повторите попытку.
Launching Visual Studio Code
Ваша кодовая зона откроется, как только будет готова.
Возникла проблема с инициализацией вашей области кода, пожалуйста, попробуйте еще раз.
Latest commit
Последняя информация о привязке не может быть загружена.
DALL-E 2 — Pytorch
Реализация DALL-E 2, обновленной нейронной сети OpenAI для синтеза текста и изображения, в Pytorch.
Основным новшеством, по-видимому, является дополнительный уровень косвенного подключения к предыдущей сети (либо автопилотный трансформатор, либо диффузная сеть), который позволяет встраивать текст CLIP на основе изображений. В частности, в этом хранилище генерируется только сеть приоритетной диффузии, так как это самый мощный вариант (который, кстати, также включает причинный трансформатор в качестве сети дефторизации 😂 ).
В настоящее время эта модель является SOTA для преобразования текста в изображение.
Пожалуйста, присоединяйтесь к нам, если вы заинтересованы в том, чтобы помочь размножить его с сообществом LAION | Yannic Interview
Начиная с 23.5.22, она больше не является SOTA. SOTA будет здесь. Публикации Jax, а также проект «текст в видео» переходят на архитектуру Imagen, поскольку она намного проще.
Исследовательская группа использовала код из этого репозитория для обучения функциональной диффузии, опережающей поколения CLIP. Они представят свою работу после публикации предварительной статьи. Это, наряду с собственными экспериментами Кэтрин, подтверждает вывод OpenAI о том, что дополнительное предшествование увеличивает разнообразие поколений.
Декодер теперь работает для безусловной генерации в моей экспериментальной установке для оксфордских цветов. Два исследователя также подтвердили, что декодер работает у них.

в процессе работы в 21к шагов
Джастин Пинкни успешно обучил предыдущую диффузию в хранилище для приложения CLIP to Stylegan2 text to image.
Ромен без проблем расширил обучение до 800 GPU с помощью имеющихся скриптов.
- LAION обучает предыдущие модели. Контрольные точки доступны в 🤗 huggingface, а статистика тренировок доступна в 🐝 WANDB.
- Декодер — текущий тестовый запуск 🚧
- Декодер — Еще один тестовый запуск с разреженным вниманием.
- DALL-E 2 🚧 — DALL-E 2 Laion Repository
Эта библиотека не смогла бы продвинуться так далеко без помощи Европейской комиссии.
-
за распределенный обучающий код для диффузии prior за распределенный обучающий код для декодера, а также dataloaders за работу над первоначальным скриптом обучения диффузии за пересмотр запросов и управление проектом, и xiankgx за вопросы и ответы и обнаружение критических ошибок для выявления проблем с изменением размера кондиционера с низким разрешением, за обучение апсемплера, в дополнение к различным другим исправлениям ошибок, за предложение использовать апсемплер pixel shuffle, за исправление артефактов шашечного поля, за советы по щедрому спонсорству, и особенно Сильвену за библиотеку Accelerate для einops, незаменимый инструмент для работы с тензорами.
. и многие другие. Спасибо! 🙏
Обучение DALLE-2 состоит из трех этапов, причем обучение CLIP является самым важным.
Для обучения CLIP можно использовать пакет x-clip или присоединиться к LAION discord, где уже предпринимаются многочисленные попытки репликации.
В этом репозитории будет продемонстрирована интеграция с x-clip для начинающих.
Затем необходимо обучить декодер, который будет учиться генерировать изображения на основе встраивания изображений, полученных из CLIP, обученного выше.
Например, вы можете загрузить старую картину, находящуюся в общественном достоянии, такую как «Мона Лиза», или другую свободную работу, например, фотографию Creative Commons.
Могут ли музыканты использовать сгенерированные нейросетями изображения
По словам Руслана Тихонова, дистрибьютор, загрузивший релиз на стриминговые сервисы, не возражал против использования такого изображения в качестве обложки альбома. Как упоминалось ранее, разработчики DALL-E 2 разрешили использовать все изображения, созданные на платформе, в коммерческих целях.
Мы уточнили у Екатерины Калиничевой, партнера юридической фирмы «Семенов и Певзнер», могут ли изображения, сгенерированные нейронными сетями, использоваться в стриминговых сервисах, социальных сетях, постерах и мерчендайзинговых статьях музыкантов.
«На этот вопрос трудно ответить однозначно, нужно рассматривать каждый случай индивидуально. Есть несколько общих моментов, которые необходимо учитывать. Нейронная сеть может создавать известные объекты (включая произведения и торговые марки), которые могут нарушать права правообладателей. Поэтому любой, кто использует такой объект в качестве изображения для обложки публикации, рискует стать нарушителем. Права на производные произведения, созданные с помощью нейронной сети, могут принадлежать их создателям при соблюдении определенных условий. Кроме того, платформы содержат условия использования сгенерированных объектов, которые могут варьироваться в зависимости от приобретенного ценового плана, и эти условия прямо указаны в условиях Midjournal», — пояснила Кэтрин.
Мы также спросили Екатерину, какие запросы пользователей DALL-E 2 и Midjournal могут вызвать проблемы с точки зрения российского законодательства.
Адвокат дал следующий совет:
- Не используйте в качестве основы для создания фотографий любые другие изображения, работы или логотипы, права на которые вам не принадлежат (например, простые изображения из интернета).
- Не создавайте изображения и не выбирайте предложенные искусственным интеллектом изображения, напоминающие логотипы известных брендов.
- Внимательно ознакомьтесь с применимыми условиями лицензирования платформ. Часто существуют условия, предоставляющие платформе и другим пользователям право использовать и изменять созданные вами изображения. В этом случае возможно, что кто-то другой имеет аналогичную защиту от высвобождения.
Смогут ли музыканты отказаться от услуг дизайнеров
Алексей Евдокимов из TBTBO Brand Mastering называет новую технологию «gamechanger» и говорит, что «это не просто очередное знаковое событие, а новый юбилейный виток для всей креативной индустрии».
«Явное преимущество для художников заключается в том, что вам не нужно тратить много времени и денег на производство. Вы визуализируете свою идею за минуту, прямо у себя в голове. А телеведущий добавляет щепотку своего собственного безумия. Это своего рода новый симбиоз творческого мышления. Но в процессе мы увидим такое интенсивное заигрывание с технологиями, что в какой-то момент они превратятся из чего-то необычного, что художник может использовать, чтобы выделиться, в нечто совершенно обыденное и повсеместное. Для людей, которые не только ищут уникальный звук, но и вообще хотят идти по пути собственной идентичности, AI будет не самым очевидным выбором», — размышляет Евдокимов.
На вопрос, не разорит ли массовое использование нейронных сетей дизайнеров и иллюстраторов, Алексей отвечает: «Возможно, определенная категория дизайнеров действительно откажется, но до этого еще далеко. Конечно, у многих иллюстраторов возникнут проблемы. В ближайшем будущем, конечно, появятся люди, которые будут профессионально создавать нужные приложения. Это уже очень хороший инструмент. Но здесь вступает в игру другой, более важный момент: Если нейронная сеть обучает себя через все запросы и изменения, насколько она будет разрушена или улучшена вмешательством людей, которые знают, как ею манипулировать?».
Текст генерации: умный красный робот серфит на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство, очень красивое искусство
Diffusion Models
Диффузионные модели — это генеративные модели, основанные на трансформаторах. Они берут набор данных, например, фотографию, и постепенно добавляют шум, пока она не станет неузнаваемой. И с этой точки они пытаются восстановить изображение в его первоначальном виде. Таким образом, они учатся создавать изображения или другие данные.
Назад к DALL-E 2
Why Waste Time With A Prior Model?
В этот момент может возникнуть вопрос: «Зачем вообще беспокоиться о предшественнике?».
Что ж, авторы думали так же. Поэтому они провели несколько экспериментов. Давайте рассмотрим пример из статьи, чтобы понять, почему необходим априор:
Для надписи «картина маслом с изображением корги в шляпе для вечеринки» -.
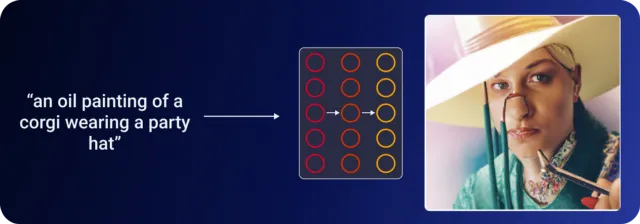
Если передать надпись непосредственно в декодер, вы увидите изображение мужчины в шляпе.
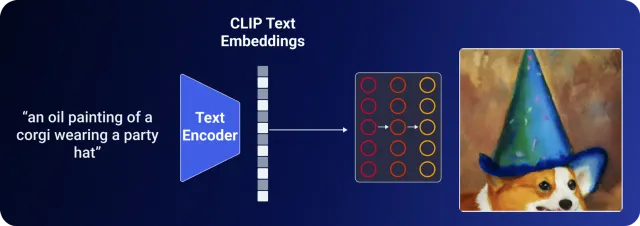
Если добавить в декодер вставку CLIP, то получится изображение корги, частично выведенного из кадра.

Наконец, использование ранее созданных вкраплений изображений дает более качественную и полную картину.
Хотя вкрапления текста CLIP дают приемлемые результаты, удаление предшественника приводит к потере способности DALL-E 2 создавать вариации изображения. (подробнее об этом позже)
Теперь обратимся к декодеру.
Generating Image From Image Embeddings
В DALL-E 2 декодером является другая модель, разработанная OpenAI, под названием GLIDE (G uided L anguage to I mage D iffusion for Generation and E diting). GLIDE — это модифицированная модель диффузии. От чистых моделей диффузии ее отличает включение текстовой информации.
Диффузионная модель начинается со случайной выборки гауссовского шума, поэтому нет возможности контролировать этот процесс для создания конкретных изображений. Например, диффузионная модель, обученная на наборе данных собак, будет последовательно создавать фотореалистичные изображения собак. Но что, если вы хотите вывести конкретную породу собак?
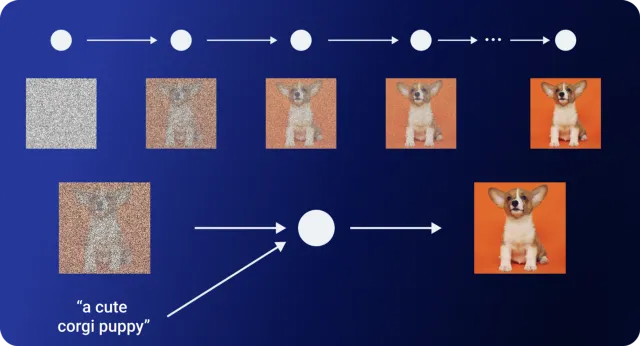
GLIDE опирается на генетический успех диффузионных моделей, расширяя процесс обучения дополнительными текстовыми вкраплениями. Это приводит к созданию условных текстовых изображений. Эта модифицированная модель GLIDE позволяет DALL-E 2 обрабатывать изображения на основе текстовых инструкций.
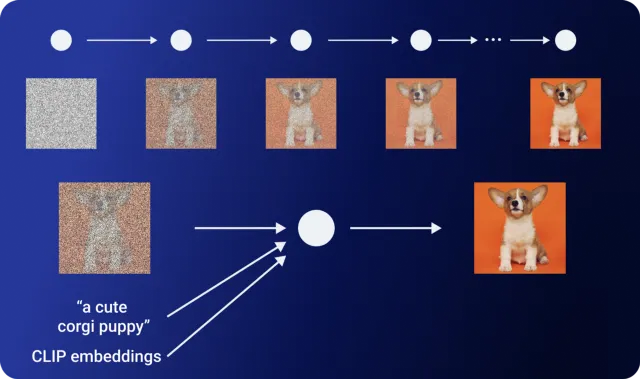
Модель GLIDE, использованная в качестве декодера в DALL-E 2, была немного изменена. Он содержит не только текстовую информацию, но и CLIP-исполнение.
Вещи, которые, как я подозреваю, не пригодятся: Интерес к расширению этических/контекстуальных границ DALL-E, идеи, связанные с NFT, очень абстрактные академические предложения, и просто отчаянное желание получить доступ.
▍ Посмотрим на несколько моих сгенерированных фаворитов

Далле-2 очень точно идентифицирует сущности, определенные в тексте. Видно, что сеть знает, что такое Москва, как выглядит Эйнштейн и как он уважает панду….. (Панда? Мы писали о быке, но это не важно). Мы также должны следить за тем, чтобы стили были определены в тексте. Меш делает хорошее различие между пиксельным, цифровым и киберпанковским стилями. Мне это нравится! Давайте еще поиграем!
Допустим, мне очень нравятся красные роботы, и я хочу сделать плакат для своей стены и т.д. Давайте поиграем в конструктор!
Я : Я хочу, чтобы это был красный робот, катающийся на волне! Дизайнер : Нет проблем, вот 4 варианта!

Создание текста: Красный робот серфит на волне
Я: Робот хороший, но могу ли я иметь остров на заднем плане? Дизайнер : Да, вот варианты!

Generation Text: Красный робот катается на волне, остров на заднем плане.
Я: Уже лучше, но все равно не то. Я хочу масляную краску! Дизайнер: Хорошо, я буду рисовать маслом. Для меня это не сложно!

Текст поколения : Красный робот серфингист на волне, остров на заднем плане, картина маслом.
Я: О, это именно то, что я хотел. И, возможно, некоторые тропические тоже…. И сделайте робота трехмерным! И цифровой! Кроме того, постеры сейчас в тренде! Как насчет не красного? Дизайнер: Что тропическое? 3D и цифровые? Как плакат? Эй, мужик, как дела! Время пришло! Выбирайте!

Generation text: красный робот серфинг на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство

Текст генерации: красный робот серфит на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство, как киноафиша

Текст поколения: Красный робот катается на волне с киберсерфборда, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство, очень красивое искусство

Текст генерации: умный красный робот серфит на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство, очень красивое искусство

Generation text: Робот серфинг на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство, цифровое искусство, очень красивое искусство

Текст поколения: Зеленый робот серфинг на волне, остров на заднем плане, картина маслом, тропический стиль, 3d, цифровое искусство
▍ Доводим любителей пиксельных изображений до экстаза 🙂
Разве я не говорила вам, что люблю пиксель-арт! Так давайте попросим Далле-2 нарисовать нам несколько!

Generation Text.

Текст генерации: множество маленьких людей входят в большой заброшенный лунный замок с моста, внутри замка фиолетовый свет, вид с улицы, очень очень красивый пиксель-арт

Текст генерации: очень красивая гигантская утка купается в Москве-реке, цифровое искусство, пиксель-арт

Текст генерации: тропический астронавт лежит под пальмой с коктейлем, вид на галактику, цифровое искусство, розовый фон, пиксель-арт

Генерация текста: Пиксельное искусство, синий кот в космосе, цифровое искусство, галактический фон, как взрыв тумана, вид с земли, пиксельное искусство.
▍ Совмещаем несовместимое
Зачем нам нужен Photoshop, если все это может сделать Dalle-2? Давайте смешаем кошек со случайными предметами. У нас есть кусочек!
Кошка + подводная лодка =

Generation text: химера кошачьей подводной лодки, цифровое искусство

Generation text: химера кошачьей подводной лодки, цифровое искусство
Кошка + Робот =

Текст поколения: кошка-робот химера-химера, цифровое искусство

Текст поколения: Кот-трансформер Химера, цифровое искусство
кошка + человек =

Generation text: кошачье-человеческая химера, цифровое искусство

Generation text: химера человек-кошка, цифровое искусство
Декодер теперь работает для безусловной генерации в моей экспериментальной установке для оксфордских цветов. Два исследователя также подтвердили, что декодер работает у них.
How DALL-E 2 Actually Works
Как на самом деле работает новаторская модель DALL-E 2 от OpenAI? Узнайте секреты игры DALL-E 2 в этом подробном руководстве.

В начале этого месяца была запущена революционная модель DALL-E 2 от OpenAI, которая установила новые стандарты в области создания и редактирования изображений. С помощью короткого текстового запроса DALL-E 2 может создавать совершенно новые изображения, которые объединяют разрозненные и несвязанные объекты семантически правдоподобными способами, как, например, следующие изображения, созданные с помощью запроса «миска супа, которая является порталом в другое измерение как цифровое искусство».

Различные изображения, созданные DALL-E 2 с помощью вышеупомянутой подсказки (источник).
DALL-E 2 даже способен модифицировать существующие изображения, создавать варианты изображений, сохраняющие их важные особенности, и интерполировать между двумя входными изображениями. Впечатляющие результаты DALL-E 2 заставили многих задаться вопросом, как именно работает такая мощная модель под капотом.
В этой статье мы подробно рассмотрим, как DALL-E 2 удается создавать потрясающие изображения, подобные тем, что показаны выше. Предоставляется много базовой информации, а уровни объяснения широкие, что делает эту статью подходящей для читателей с разным уровнем опыта в машинном обучении. Давайте погрузимся!
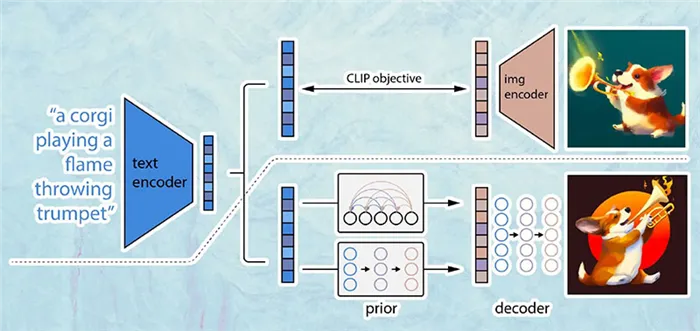
How DALL-E 2 Works: A Bird’s-Eye View
Прежде чем перейти к деталям работы DALL-E 2, давайте сначала получим общее представление о том, как DALL-E 2 создает изображения. Хотя DALL-E 2 может выполнять множество задач, включая обработку изображений и интерполяцию, упомянутые выше, в этой статье мы сосредоточимся на создании изображений.

Вид с высоты птичьего полета на процесс создания DALL-E 2 (изменено из источника).
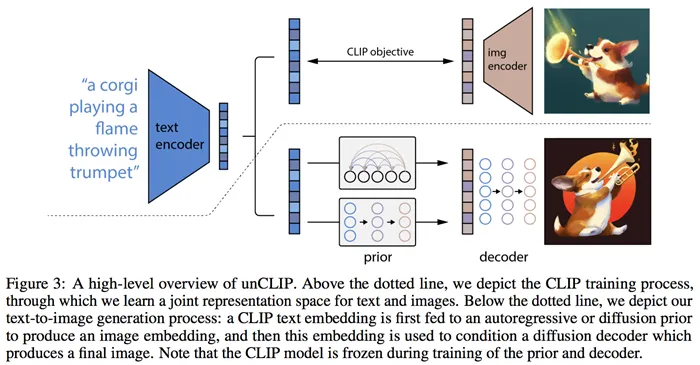
На самом высоком уровне управление DALL-E 2 очень простое:
- Сначала текстовая подсказка вводится в текстовый кодировщик, который обучен отображать подсказку в пространстве представления.
- Затем текстовая кодировка сопоставляется моделью под названием prior с соответствующей кодировкой изображения, которая сопоставляет семантическую информацию подсказки, содержащуюся в текстовой кодировке.
- Наконец, декодер изображения стохастически генерирует изображение, которое является визуальным проявлением этой семантической информации.
С высоты птичьего полета — все! Конечно, в реализации есть много интересных особенностей, о которых мы поговорим ниже. Если вы хотите узнать больше, не вдаваясь в подробности, или если вы предпочитаете смотреть, а не читать, вы можете посмотреть видео с анализом фильма DALL-E 2 здесь:
How DALL-E 2 Works: A Detailed Look
Теперь пришло время заняться каждым из вышеперечисленных этапов по отдельности. Сначала рассмотрим, как DALL-E 2 учится ассоциировать взаимосвязанные абстрактные картинки текста и изображения.
Step 1 — Linking Textual and Visual Semantics
После введения фразы «плюшевый медведь катается на скейтборде на Таймс-сквер» в DALL-E 2 появляется следующее изображение:

Источник
Откуда DALL-E 2 знает, как такой текстовый термин, как «плюшевый мишка», проявляется в визуальном пространстве? Связь между семантикой текста и его визуальным представлением в DALL-E 2 изучается с помощью другой модели OpenAI под названием CLIP (C ontrastive L anguage- I mage P re-training).
CLIP был обучен на сотнях миллионов изображений и подписей к ним, чтобы узнать, как определенный фрагмент текста связан с изображением. То есть, вместо того, чтобы пытаться предсказать, как надпись будет сочетаться с изображением, CLIP просто изучает, насколько конкретная надпись связана с изображением. Эта репрезентативная, а не прогностическая цель позволяет CLIP изучать связь между текстовыми и визуальными представлениями одного и того же абстрактного объекта. Вся модель DALL-E 2 основана на способности CLIP изучать семантику естественного языка. Итак, давайте рассмотрим, как происходит обучение CLIP, чтобы понять его внутреннюю работу.
CLIP Training
Основы обучения CLIP довольно просты:
- Сначала все изображения и связанные с ними метки проходят через соответствующие кодирующие устройства, которые отображают все объекты в m-мерном пространстве.
- Затем рассчитывается косинусное сходство каждой пары (изображение, текст).
- Цель обучения — одновременно максимизировать косинусное сходство между N правильно закодированными парами изображение/картинка и минимизировать косинусное сходство между N 2 — N неправильно закодированными парами изображение/картинка.
Этот процесс обучения показан ниже:
Более подробная информация о тренинге
Более подробную информацию о процессе обучения CLIP можно найти ниже.
- Cosine Similarity
- Косинусное сходство двух векторов — это просто квадратное произведение двух векторов, увеличенное на произведение их величин. Он измеряет угол между двумя векторами в векторном пространстве и, в контексте машинного обучения, определяет, насколько «похожи» два вектора друг на друга. Если мы предположим, что каждое «направление» в векторном пространстве имеет концепцию, то косинусное сходство между двумя закодированными векторами измеряет, насколько «похожи» концепции, представленные векторами.
- CLIP обучается на наборе данных WebImageText, который состоит из 400 миллионов пар изображений и связанных с ними меток на естественном языке (не путать с Image Text из Википедии).
- Параллельность процедуры обучения CLIP очевидна сразу — все кодировки и косинусные сходства могут быть вычислены параллельно.
- Кодировщик текста является трансформатором
- Кодер изображения представляет собой преобразователь изображения
Significance of CLIP to DALL-E 2
CLIP важен для DALL-E 2, потому что он в конечном итоге определяет, насколько семантически релевантен отрывок на естественном языке визуальному понятию, что имеет решающее значение для создания изображений на основе текста.











